Predicting Number of Upvotes for A Headline in Hacker News
Introduction
You can download the dataset here (stories_cleaned.csv).
The dataset contains more than 1 million rows of entry, for simplicity, we will use only random 3000 rows to
make our exciting predictions!
Background
Hacker News is a social news website focusing on computer science and entrepreneurship.
Users can upvote those news and the news with most upvotes will make it to the front page, making them
more visible to the community.
Technologies
Python, Pandas, Numpy, Scikit-learn, Natural Language Processing (bag-of-words model).
Goal
We want to predict the number of upvotes a headline would receive from the Hacker News community.
And we
will accomplish this in 3 high-level steps:
- Read in and clean the dataset
- Train the model
- Make a prediction
Let's begin!
Step 1: Read in and clean the dataset
Let's first import pandas and numpy
import pandas as pd
import numpy as np
stories = pd.read_csv("stories_cleaned.csv")
stories = stories.dropna() # drop rows which contain missing values
stories = stories.sample(n=3000) # randomly sample only 3000 rows
stories.columns = ["num_upvotes", "headline"] # set column names
Step 2: Train the model
To keep this demo short and sweet, I'll skip some explanations of how the code works. However, I've added in
comments to facilitate your understanding of the code.
An important vocabulary to know however, is the word
"token". See "token" as an individual word in a headline and an individual word is also a "feature" in a
machine learning model.
So, "token" = "feature" = an individual word.
First, we prepare the necessary data for our model training.
Some quick points:
- We only use tokens that occur more than once as our model's features.
A token that occurs only once has no meaningful significance in telling us how that token will affect the number of upvotes a headline would receive. - We further remove some noise by removing features that occurred too seldom (<10 times) and too frequent
(>100 times).
### tokenization - breaking headlines down to individual words ###
lists_of_tokens = [] # will be a list of lists
for hl in stories["headline"]: # for each headline in the column
lists_of_tokens.append(hl.split()) # split by white space
### lowercasing and removing punctuations ###
punctuations = [",", ":", ";", ".", "'", '"', "’", "?", "/", "-", "+", "&", "(", ")"]
lists_of_tokens_cleaned = []
for token_list in lists_of_tokens:
cur_cleaned_list = []
for token in token_list: # for each token in the list
token = token.lower() # convert to all lowercase
for punc in punctuations: # remove all punctuations
token = token.replace(punc, "")
cur_cleaned_list.append(token) # append the cleaned token to cur list
lists_of_tokens_cleaned.append(cur_cleaned_list) # append the cleaned list to l_o_t_cleaned
### initiate a df with 0s ###
# find a list of unique tokens and we want only tokens that occur more than once
unique_tokens = []
once_tokens = [] # stores tokens that has occurred once
for token_list in lists_of_tokens_cleaned:
for token in token_list:
if token not in once_tokens:
once_tokens.append(token)
elif token not in unique_tokens: # ...but is in once_tokens[] then..
unique_tokens.append(token)
# create the dataframe: each row = a headline, each column = a token.
counts = pd.DataFrame(0, index=np.arange(len(lists_of_tokens_cleaned)), columns=unique_tokens)
### fill in counts for each cell ###
for row_index, token_list in enumerate(lists_of_tokens_cleaned): #enumerate() to use index
for token in token_list:
if token in unique_tokens:
counts.iloc[row_index][token] += 1 # increment count
### remove noisy tokens - occurred too seldom and too frequent ###
word_counts = counts.sum(axis=0) # sum by columns; word_counts is a Series
counts = counts.loc[:, (word_counts>=10) & (word_counts<=100)] # take only tokens that occur >10 and <100 times
# split dataset
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(counts, stories["num_upvotes"], test_size=0.2) # X is the counts of tokens
# train
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(X_train, y_train)
Step 3: Make a prediction
Let's create a function that takes in a headline and spits out a predicted number of upvotes based on our
model's knowledge :).
def upvote_predictor(headline):
# tokenization
tokenized_headline = headline.split()
# lowercasing and removing punctuations
punctuation = [",", ":", ";", ".", "'", '"', "’", "?", "/", "-", "+", "&", "(", ")"]
tokenized_headline_cleaned = []
for token in tokenized_headline:
token = token.lower()
for punc in punctuation:
token = token.replace(punc, "")
tokenized_headline_cleaned.append(token)
# get unique tokens
unique_tokens = []
once_tokens = []
for token in tokenized_headline_cleaned:
if token not in once_tokens:
once_tokens.append(token)
elif token not in unique_tokens:
unique_tokens.append(token)
# create prediction input
single_counts = pd.DataFrame(0, index=[0], columns=X_test.columns)
for token in tokenized_headline_cleaned:
if token in single_counts.columns:
single_counts[token] += 1
prediction = lr.predict(single_counts)
return prediction
# calling our custom function
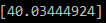
print(upvote_predictor("How many upvotes would I get?!"))
Wrap Up
If you run the code multiple times, you would notice that we will get a different predicted number of upvotes
in every run. That's because our model is trained with a different set of 3000 rows out of the original 1
million++ entries everytime!
There are certainly many optimizations that could be done to improve our model's prediction accuracy, like
using the entire dataset, adding other useful features like "length of headline", trying with different
threshold for removing noisy features etc.
But that's it for now. Thank you for accompanying me on this exciting exploration. Hope you enjoyed it like I
did!